Tensor & Tensor Train module
See also API docs for pompon.layers.tensor.Tensor & pompon.layers.tt.TensorTrain
Data Type
The type of JAX Array is usually float32, but in pompon, we set float64.
If you want default float32, change pompon.__dtype__.DTYPE to jnp.float32 before importing pompon.
Tensor
1d Tensor (vector) \(v_i\)
2d tensor (matrix) \(M_{ji}\)
3d tensor \(T_{ijk}\)
Code
T=Tensor(shape=(2, 3, 4), leg_names=['i', 'j', 'k'], dtype=float64)
T.data=Array([[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]],
[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]]], dtype=float64)tensor with batch-index \(x_{Dij}\) and \(y_{Di}\)
batch-index is set by 'D', which must be the first index.
Code
x=Tensor(shape=(10, 2, 3), leg_names=['D', 'i', 'j'], dtype=float64)
y=Tensor(shape=(10, 2), leg_names=['D', 'i'], dtype=float64)Tensor contraction
- \(u_j = \sum_{i}M_{ji}v_i\) (matrix * vector)
u=Tensor(shape=(3,), leg_names=('j',), dtype=float64)- \(u_k = \sum_{ij} T_{ijk} M_{ji}\)
- \(u_k = \sum_{ij} T_{ijk} M_{ji} v_{i}\)
This is not the same as T @ M @ v = \(L_{ki} = \left(\sum_{ij}T_{ijk} M_{ji}\right) v_{i}\)
Code
u=Tensor(shape=(4,), leg_names=('k',), dtype=float64)
L=Tensor(shape=(4, 2), leg_names=('k', 'i'), dtype=float64)- \(z_{Dj} = \sum_{i}x_{Dij}y_{Di}\) (index \(D\) will remain)
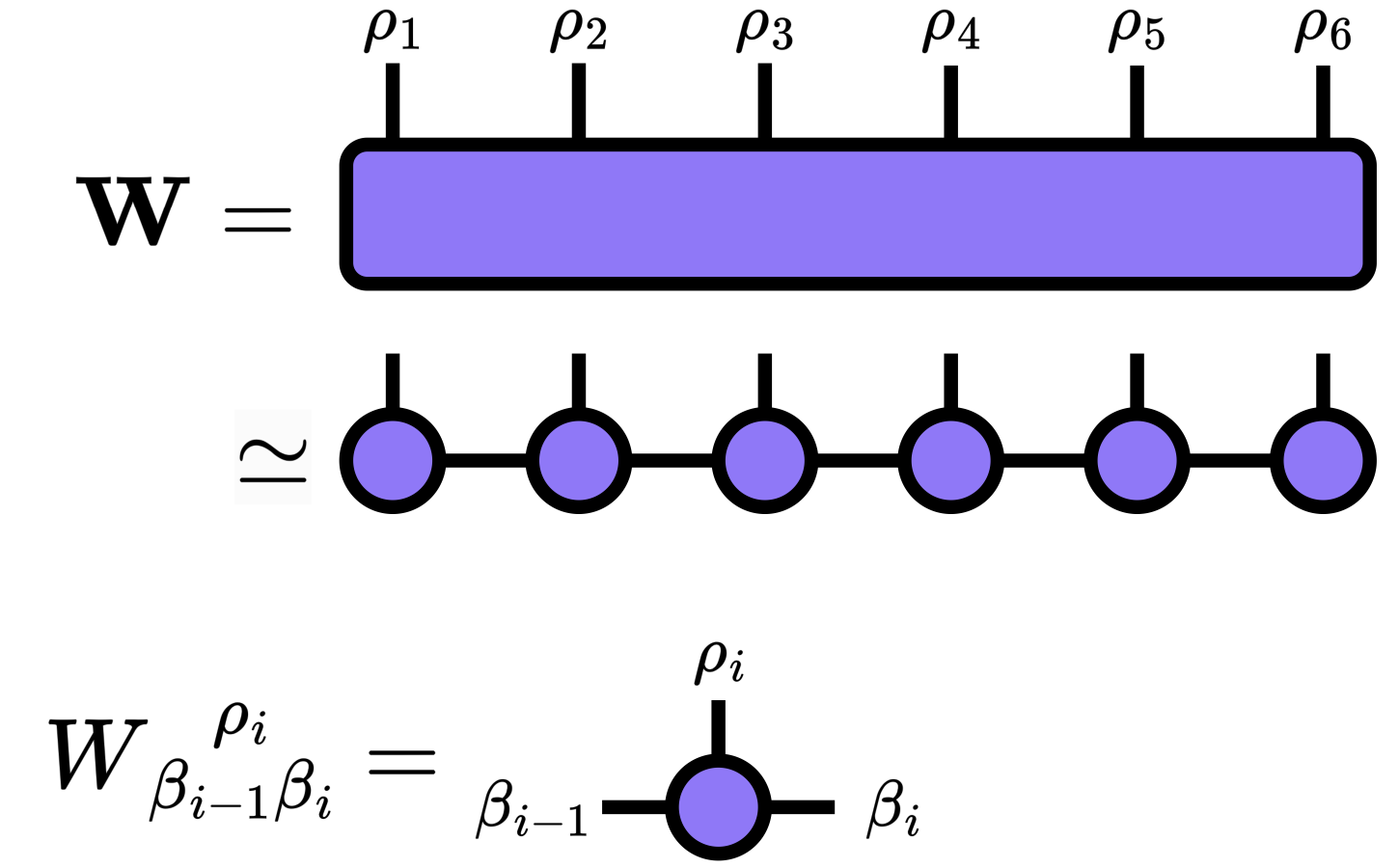
Tensor Train
Tensor train (also called matrix product states) is written by \[ A(i_1, i_2, \cdots, i_f) = \sum_{\beta_1,\beta_2,\cdots,\beta_{f-1}} \ W^{[1]}_{i_1\beta_1} W^{[2]}_{\beta_1 i_2 \beta_2} \cdots W^{[f]}_{\beta_{f-1}i_f} \]
Code
[Core(shape=(1, 3, 2), leg_names=('β0', 'i1', 'β1'), dtype=float64), Core(shape=(2, 3, 2), leg_names=('β1', 'i2', 'β2'), dtype=float64), Core(shape=(2, 3, 2), leg_names=('β2', 'i3', 'β3'), dtype=float64), Core(shape=(2, 3, 1), leg_names=('β3', 'i4', 'β4'), dtype=float64), ]
tt=TensorTrain(shape=(3, 3, 3, 3), ranks=[2, 2, 2])
tt.ndim=4
tt.ranks=[2, 2, 2][Core(shape=(1, 3, 2), leg_names=('β0', 'i1', 'β1'), dtype=float64),
Core(shape=(2, 3, 2), leg_names=('β1', 'i2', 'β2'), dtype=float64),
Core(shape=(2, 3, 2), leg_names=('β2', 'i3', 'β3'), dtype=float64),
Core(shape=(2, 3, 1), leg_names=('β3', 'i4', 'β4'), dtype=float64)]Each core has instance Tensor
Each core can be contracted as TwodotCore
B=TwodotCore(shape=(1, 3, 3, 2), leg_names=('β0', 'i1', 'i2', 'β2'))TwodotCore has a method svd() which split into two Cores again
Code
W0_next=Core(shape=(1, 3, 2), leg_names=('β0', 'i1', 'β1'), dtype=float64)
W1_next=Core(shape=(2, 3, 2), leg_names=('β1', 'i2', 'β2'), dtype=float64)Forward TensorTrain with basis batch
Code
[BasisBatch(shape=(10, 3), leg_names=['D', 'i1'], dtype=float64),
BasisBatch(shape=(10, 3), leg_names=['D', 'i2'], dtype=float64),
BasisBatch(shape=(10, 3), leg_names=['D', 'i3'], dtype=float64),
BasisBatch(shape=(10, 3), leg_names=['D', 'i4'], dtype=float64)]