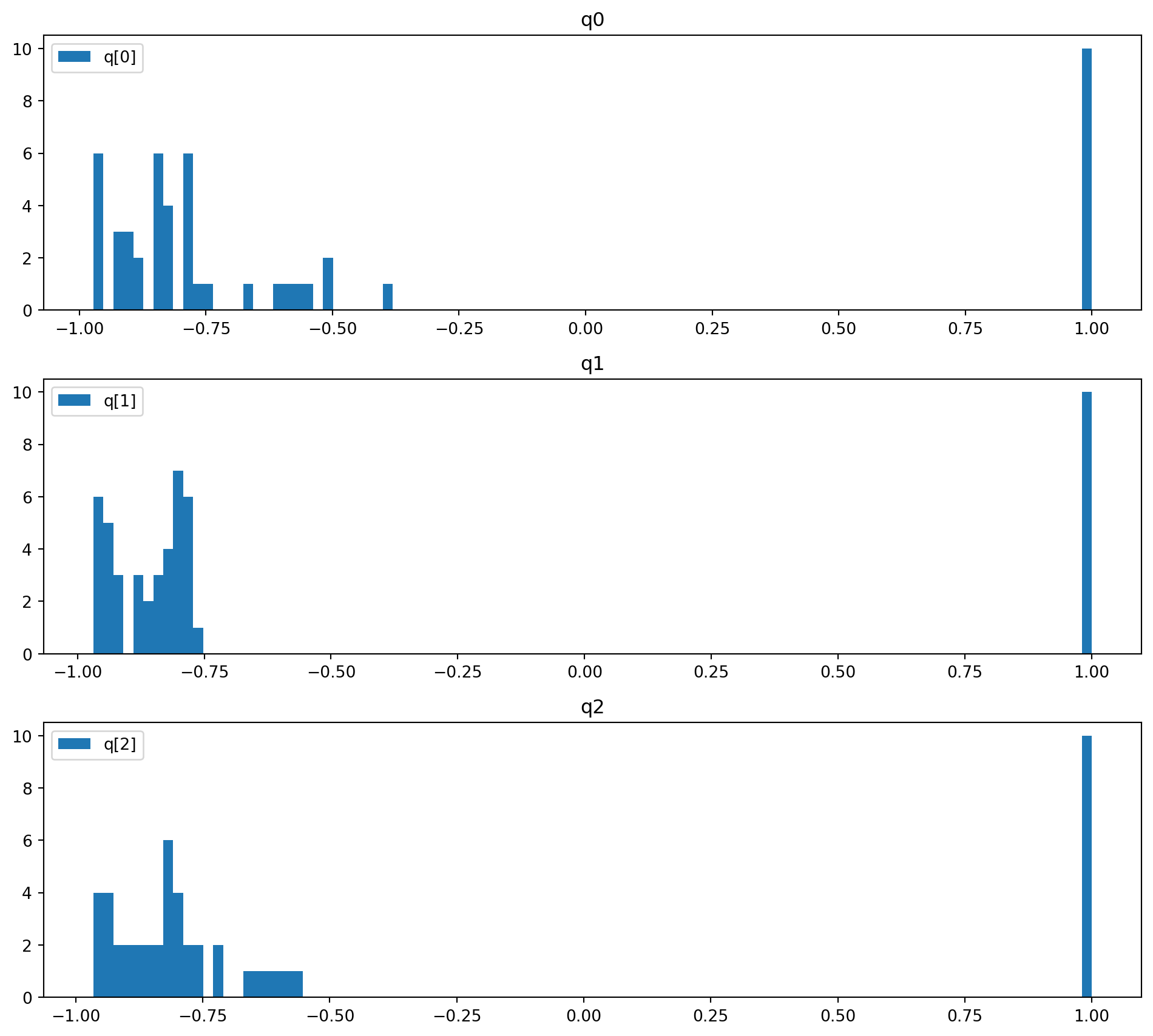
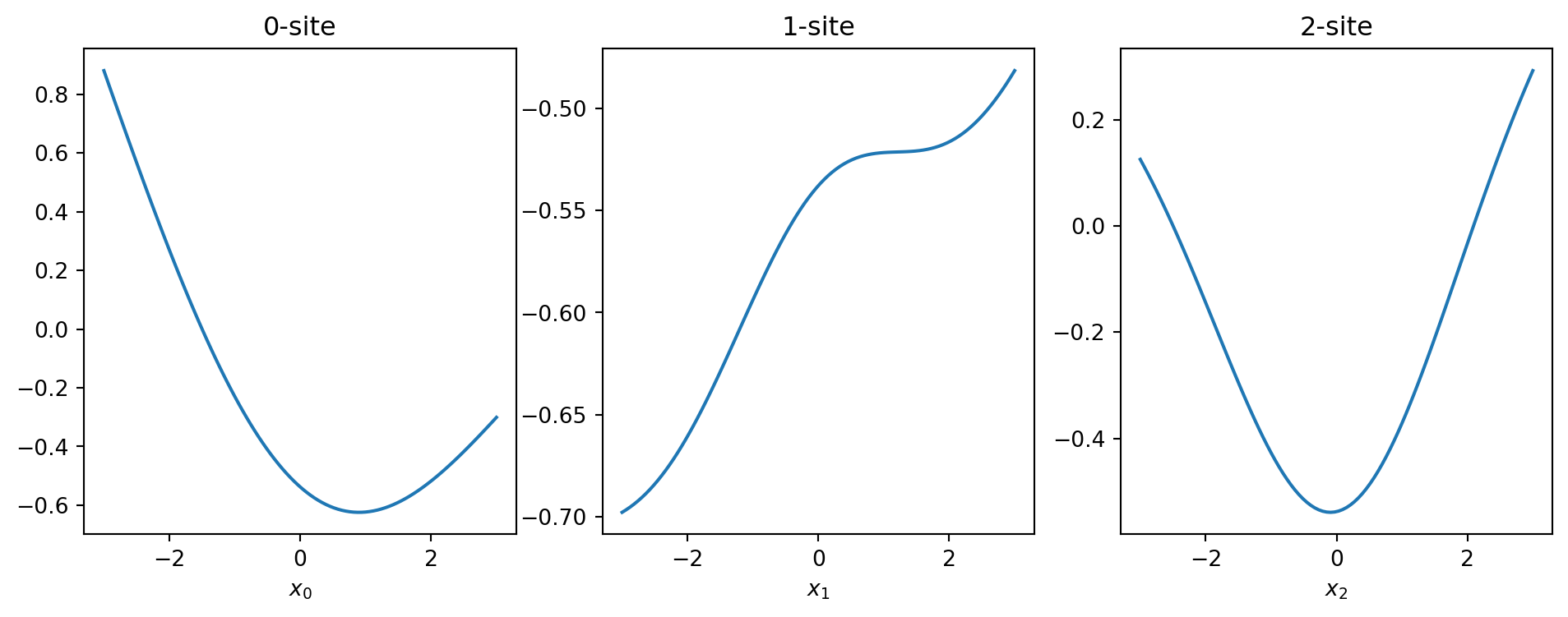
Code
(10, 1)model.NNMPO(
self
input_size
basis_size
*
hidden_size=None
bond_dim=2
output_size=1
w_scale=1.0
b_scale=0.0
w_dist='uniform'
b_dist='linspace'
x0=None
activation='silu+moderate'
random_tt=True
key=None
X_out=None
fix_bias=False
)Neural Network Matrix Product Operator

\[ \begin{align} &V_{\text{NN-MPO}}(\mathbf{x}) = \widetilde{V}_{\text{NN-MPO}}(\mathbf{q}) \notag \\ &= \label{eq:nnmpo-full} \sum_{\substack{\rho_1,\rho_2,\cdots\rho_f\\ \beta_1,\beta_2,\cdots\beta_{f-1}}} \phi_{\rho_1}(q_1) \cdots \phi_{\rho_f}(q_f) W\substack{\rho_1\\1\beta_1}W\substack{\rho_2\\\beta_1\beta_2} \cdots W\substack{\rho_f\\\beta_{f-1}1}. \end{align} \]
where \(\phi\) is an activation and \([q_1, \cdots, q_n] = [x_1, \cdots, x_n]U\) is a linear transformation.
This class mainly consists of three layers:
| Name | Type | Description | Default |
|---|---|---|---|
| input_size | int | Input size \(n\) | required |
| hidden_size | int | Hidden size \(f\) | None |
| basis_size | int | Number of basis \(N\) per mode. (\(\rho_i=1,2,\cdots,N\)) | required |
| bond_dim | int | Bond dimension \(M\) (\(\beta_i=1,2,\cdots,M\)). | 2 |
| output_size | int | Output size. Only output_size=1 is supported so far. |
1 |
| x0 | Array | Reference point for the input coordinates. \(q_0=x_0U\) and \(w(q-q_0)+b\) will be argument of the basis function. If None, x0 will be zeros. |
None |
| activation | str | activation function. See also activations. |
'silu+moderate' |
| w_scale | float | scaling factor of weights. | 1.0 |
| w_dist | str | weight distribution. Available options is written in basis. |
'uniform' |
| b_scale | float | scaling factor of biases. | 0.0 |
| b_dist | str | bias distribution. Available options is written in basis. |
'linspace' |
| random_tt | bool | if True, initialize tensor-train randomly. | True |
| X_out | Array | Project out vector from the hidden coordinates. See details on Coordinator. |
None |
| fix_bias | bool | Whether or not fix \(b\). | False |
| Name | Description |
|---|---|
| bond_dim | Get maximum bond dimension \(M_{\text{max}}\). |
| q0 | Get initial hidden coordinates \(q_0=x_0U\) |
| Name | Description |
|---|---|
| convert_to_mpo | Convert to Matrix Product Operator (MPO) |
| export_h5 | Export the model to a HDF5 file |
| force | Compute force \(-\nabla V_{\text{NN-MPO}}(\mathbf{x})\). |
| forward | Compute energy (forward propagation) \(V_{\text{NN-MPO}}(\mathbf{x})\). |
| grad | Gradient of loss function with respect to \(W\), \(w\), \(b\) and \(U\) |
| import_h5 | Import the model from a HDF5 file |
| mse | Mean squared error |
| mse_force | Mean squared error with force |
| plot_basis | Plot distribution of \(\phi\) |
| rescale | Rescale the model |
| show_onebody | Visualize one-dimensional cut. |
| update_blocks_batch | Update Left and Right blocks batch of \(W\) (tensor-train) with \(\phi\). |
Convert to Matrix Product Operator (MPO)
\[ \mathcal{W}\substack{\sigma_i^\prime\\\beta_{i-1}\beta_i \\ \sigma_{i}} = \sum_{\rho_i=1}^{N_i} W\substack{\rho_i\\\beta_{i-1}\beta_i} \langle\sigma_i^\prime|\phi_{\rho_i}^{(i)}|\sigma_i\rangle \] \[ \hat{V}_{\mathrm{NNMPO}}\left(\pmb{Q}\right) = \sum_{\{\pmb{\beta}\},\{\pmb{\sigma}\},\{\pmb{\sigma}^\prime\}} \mathcal{W}\substack{\sigma_1^\prime\\1\beta_1\\\sigma_1} \mathcal{W}\substack{\sigma_2^\prime\\\beta_1\beta_2\\\sigma_2} \cdots \mathcal{W}\substack{\sigma_f^\prime\\\beta_{f-1}1\\\sigma_f} |\sigma_1^\prime\sigma_2^\prime\cdots\sigma_f^\prime\rangle \langle\sigma_1\sigma_2\cdots\sigma_f| \]
| Name | Type | Description | Default |
|---|---|---|---|
| basis_ints | list[np.ndarray] | List of the integrals between potential basis function and wave function basis function \(\langle\sigma_i\|\phi_{\rho_i}^{(i)}\|\sigma_i\rangle\). The length of the list must be equal to the hidden size \(f\). The list element is an array with shape \((d_i, N_i, d_i)\) where \(d_i\) is the number of basis functions of the wave function and \(N_i\) is the number of basis functions of the potential. If you want raw tensor-train data, you can address by nnmpo.tt.W.data. |
required |
| Name | Type | Description |
|---|---|---|
| list[np.ndarray] | list[np.ndarray]: MPO. The length of the list is equal to the hidden size. The \(i\)-th element is an array with shape \((M_i, d_i, d_i, M_{i+1})\) where \(M_i\) is the bond dimension. |
import numpy as np
import pompon
model = pompon.NNMPO(input_size=3, hidden_size=3, basis_size=5)
# Basis functions can be evaluated ``by model.basis.phis.forward(q, model.q0)``
# This is just an dummy example.
basis_ints = [np.random.rand(4, 5, 4) for _ in range(3)]
mpo = model.convert_to_mpo(basis_ints)
for i in range(3):
print(f"{mpo[i].shape=}")mpo[i].shape=(1, 4, 4, 2)
mpo[i].shape=(2, 4, 4, 2)
mpo[i].shape=(2, 4, 4, 1)Export the model to a HDF5 file
| Name | Type | Description | Default |
|---|---|---|---|
| path | str | path to the HDF5 file | required |
Compute force \(-\nabla V_{\text{NN-MPO}}(\mathbf{x})\).
| Name | Type | Description | Default |
|---|---|---|---|
| x | Array | input tensor with shape \((D,n)\) | required |
| Name | Type | Description |
|---|---|---|
| force | Array | force tensor with shape \((D,n)\) |
Compute energy (forward propagation) \(V_{\text{NN-MPO}}(\mathbf{x})\).
| Name | Type | Description | Default |
|---|---|---|---|
| x | Array | input tensor with shape \((D,n)\) where \(D\) is the batch size and \(n\) is the input size. | required |
| Name | Type | Description |
|---|---|---|
| Array | Array | output tensor with shape \((D,1)\) |
model.NNMPO.grad(
x
y
*
loss='mse'
twodot_grad=False
onedot_grad=False
basis_grad=False
coordinator_grad=False
q=None
basis=None
use_auto_diff=False
lambda1=0.0001
mu1=0.1
mu2=1.0
f=None
wf=1.0
to_right=True
)Gradient of loss function with respect to \(W\), \(w\), \(b\) and \(U\)
| Name | Type | Description | Default |
|---|---|---|---|
| x | Array | input tensor with shape \((D,n)\) where \(D\) is the batch size and \(n\) is the input size. | required |
| y | Array | output tensor with shape \((D,1)\) | required |
| loss | str | loss function. | 'mse' |
| twodot_grad | bool | if True, compute gradient with respect to \(B\). Defaults to False. | False |
| onedot_grad | bool | if True, compute gradient with respect to \(C\). Defaults to False. | False |
| basis_grad | bool | if True, compute gradient with respect to \(w\) and \(b\). Defaults to False. | False |
| coordinator_grad | bool | if True, compute gradient with respect to \(U\). Defaults to False. | False |
| q | Array | hidden coordinates with shape \((D,f)\) where \(f\) is the hidden dimension. Defaults to None. If None, it is computed from \(x\). | None |
| basis | list[Array] | basis with shape \(f\times(D,N)\) where \(N\) is the basis size. Defaults to None. If None, it is computed from \(q\). | None |
| use_auto_diff | bool | if True, use auto differentiation. Otherwise, use analytical formula. Defaults to False. | False |
| lambda1 | float | EXPERIMENTAL FEATURE! regularization parameter. if not 0, add L1 regularization + entropy penalty. | 0.0001 |
| mu1 | float | EXPERIMENTAL FEATURE! L1 penalty parameter. | 0.1 |
| mu2 | float | EXPERIMENTAL FEATURE! entropy penalty parameter. | 1.0 |
| f | Array | force with shape \((D,n)\). | None |
| wf | float | Weight \(w_f\) of force term in loss function. | 1.0 |
| to_right | bool | if True, twodot core index is (tt.center, tt.center+1) otherwise (tt.center-1, tt.center). |
True |
| Name | Type | Description |
|---|---|---|
| list[Parameter] | list[Parameter]: list of parameters with gradients |
import numpy as np
x = np.random.rand(10, 3)
y = np.random.rand(10, 1)
f = np.random.rand(10, 3)
import pompon
model = pompon.NNMPO(input_size=3, hidden_size=3, basis_size=5)
params = model.grad(x, y, f=f,
basis_grad=True, coordinator_grad=True)
for param in params:
print(f"{param.name=}, {param.data.shape=}")
param.data -= 0.01 * param.gradparam.name='w0', param.data.shape=(4,)
param.name='b0', param.data.shape=(4,)
param.name='b2', param.data.shape=(4,)
param.name='w2', param.data.shape=(4,)
param.name='w1', param.data.shape=(4,)
param.name='b1', param.data.shape=(4,)
param.name='U', param.data.shape=(3, 3)Import the model from a HDF5 file
| Name | Type | Description | Default |
|---|---|---|---|
| path | str | path to the HDF5 file | required |
| Name | Type | Description |
|---|---|---|
| Model | Model | model instance |
Mean squared error
| Name | Type | Description | Default |
|---|---|---|---|
| x | Array | input tensor with shape \((D,n)\) where \(D\) is the batch size and \(n\) is the input size. | required |
| y | Array | output tensor with shape \((D,1)\) | required |
| Name | Type | Description |
|---|---|---|
| float | float | mean squared error |
Mean squared error with force
| Name | Type | Description | Default |
|---|---|---|---|
| x | Array | input tensor with shape \((D,n)\) where \(D\) is the batch size and \(n\) is the input size. | required |
| f | Array | force tensor with shape \((D,n)\) | required |
Plot distribution of \(\phi\)
| Name | Type | Description | Default |
|---|---|---|---|
| x | Array | input tensor with shape \((D,n)\) where \(D\) is the batch size and \(n\) is the input size. | required |
Rescale the model
Learning should be done with the normalized input and output. But, when the model is used for prediction, it is better to rescale the input and output to the original scale.
Input scale and output scale are attributed to the basis.phi.w.data and tt.norm.data, respectively.
| Name | Type | Description | Default |
|---|---|---|---|
| input_scale | float | scaling factor of input | required |
| output_scale | float | scaling factor of output | required |
import numpy as np
import pompon
x = np.random.rand(10, 3)
y = np.random.rand(10, 1)
x_scale = x.std()
y_scale = y.std()
x /= x_scale
y /= y_scale
model = pompon.NNMPO(input_size=3, hidden_size=3, basis_size=5)
# Some learning process with normalized input and output
model.rescale(input_scale=x_scale, output_scale=y_scale)Visualize one-dimensional cut.
Update Left and Right blocks batch of \(W\) (tensor-train) with \(\phi\).
| Name | Type | Description | Default |
|---|---|---|---|
| x | Array | input tensor with shape \((D,n)\) where \(D\) is the batch size | required |
| q | Array | hidden coordinates with shape \((D,f)\) where \(f\) is the hidden dimension. If already computed, set this argument to avoid redundant computation. | None |
| basis | list[Array] | \(\phi_{\rho_i}(q_i)\) with shape \((D,N)\). If already computed, set this argument to avoid redundant computation. | None |
| is_onedot_center | bool | if True, update \(L[1],...,L[p-1],R[p+1],...R[f]\) with the new basis. Otherwise, update \(L[1],...,L[p-1],R[p+2],...R[f]`\). | False |
model.tt.center=0
model.tt.left_blocks_batch=[LeftBlockBatch(shape=(10, 1), leg_names=('D', 'β0'), dtype=float64)]
model.tt.right_blocks_batch=[RightBlockBatch(shape=(10, 1), leg_names=('D', 'β3'), dtype=float64), RightBlockBatch(shape=(10, 2), leg_names=('D', 'β2'), dtype=float64), RightBlockBatch(shape=(10, 2), leg_names=('D', 'β1'), dtype=float64)]